Leveraging Delta Kernel for Multi-Engine Interoperability in Delta Lake 4.0
Delta Lake 4.0 introduces Delta Kernel, a pivotal step towards seamless multi-engine interoperability. This article explores how Delta Kernel simplifies connector development, enabling diverse data engines to interact with Delta Lake tables efficiently.
In the evolving landscape of data engineering, the need for seamless interoperability across multiple data processing engines is more critical than ever. Delta Lake 4.0 addresses this challenge with the introduction of Delta Kernel, a framework designed to simplify the development of connectors that enable various engines to interact with Delta Lake tables. This advancement is particularly significant for organizations leveraging diverse analytics tools, as it ensures consistent data access and manipulation across platforms.
Why Multi-Engine Interoperability Matters
In practice, data ecosystems are rarely homogeneous. Enterprises often employ a mix of processing engines like Apache Spark, Flink, Trino, and others, each optimized for specific workloads. The challenge arises when these engines need to interact with a unified data source without compromising on performance or consistency. Delta Kernel facilitates this by abstracting the complexities of the Delta Lake protocol, allowing developers to focus on building robust connectors without delving into the intricate details of the underlying data format [1][3].
Understanding Delta Kernel
Delta Kernel is a set of APIs that standardizes the way connectors interact with Delta Lake tables. It abstracts protocol details, providing a stable interface for reading and writing data. This is crucial for maintaining compatibility as Delta Lake evolves, ensuring that connectors can support new features without extensive rewrites [3]. The Kernel supports both Java and Rust, catering to a wide range of development environments and use cases.
How It Works
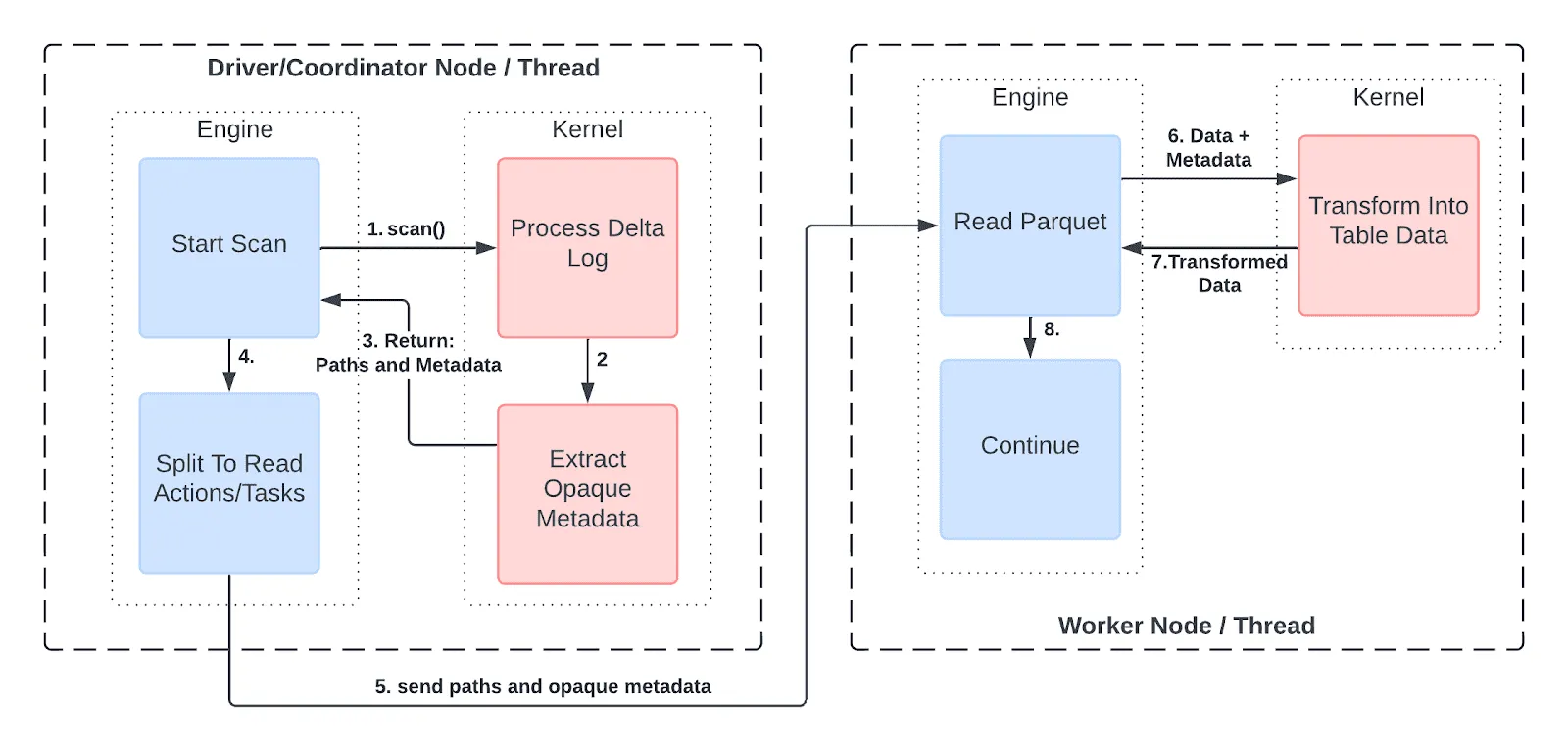
At its core, Delta Kernel operates by interpreting the Delta Lake transaction log, which maintains the state of the table and ensures ACID compliance. By providing a consistent API, Delta Kernel allows connectors to perform operations like scans and writes efficiently, regardless of the engine they are built for. This approach not only simplifies connector development but also enhances performance by optimizing how data is accessed and manipulated [3].
Walking Through a Delta Kernel Integration
To illustrate the practical application of Delta Kernel, consider integrating it with Apache Flink. The process begins by setting up a Flink environment and configuring it to use the Delta Kernel Java API. This involves adding the necessary dependencies to your project and initializing the Delta Kernel within your Flink job.
import io.delta.kernel.client.DeltaKernel; import io.delta.kernel.client.DeltaKernelBuilder; DeltaKernel deltaKernel = new DeltaKernelBuilder() .setLogStoreProvider(new S3LogStoreProvider()) .build(); // Use DeltaKernel to read from a Delta table DataStream<Row> deltaStream = env.fromSource( new DeltaSource(deltaKernel, "s3://path/to/delta-table"), WatermarkStrategy.noWatermarks(), "Delta Source");
In this example, the DeltaKernel object is configured to interact with a Delta table stored on S3. The DeltaSource is then used to create a Flink DataStream, enabling real-time data processing. This setup abstracts the complexities of the Delta Lake protocol, allowing Flink to seamlessly read from the Delta table without additional overhead [3].
Common Mistakes and Pitfalls
One issue teams discover after going to production is underestimating the complexity of maintaining compatibility with evolving Delta Lake features. While Delta Kernel simplifies this process, it's essential to stay updated with the latest API changes and ensure that connectors are tested against new Delta Lake releases. Another common pitfall is neglecting to optimize the underlying storage configuration, which can lead to performance bottlenecks when scaling operations [3][8].
When to Use Delta Kernel
Delta Kernel is the right tool when your organization relies on multiple data processing engines that need to interact with Delta Lake tables. It simplifies development and ensures consistent performance across platforms. However, if your data architecture is predominantly based on a single engine, the added complexity of integrating Delta Kernel may not be justified. In such cases, native Delta Lake support within your primary engine might suffice [1][3].
In conclusion, Delta Kernel represents a significant step forward in achieving true multi-engine interoperability within the Delta Lake ecosystem. By abstracting protocol complexities and providing a stable API, it empowers developers to build connectors that are both robust and future-proof, ensuring seamless data operations across diverse analytics environments.
- Home | Delta Lakehttps://delta.io/
- Delta Lake 4.0 Preview | Delta Lakehttps://delta.io/blog/delta-lake-4-0/
- Delta Kernel - Building Delta Lake connectors, made simple | Delta Lakehttps://delta.io/blog/delta-kernel/
- Welcome to Delta Lake’s Python documentation page — delta-spark 4.0.1 documentationhttps://docs.delta.io/api/latest/python/spark/
- A Year of Interoperability: How Enterprises Are Scaling Governance with Unity Catalog | Databricks Bloghttps://www.databricks.com/blog/year-interoperability-how-enterprises-are-scaling-governance-unity-catalog
- A Guide to Delta Lake Sessions at Data+AI Summit | Delta Lakehttps://delta.io/blog/guide-delta-ai-summit/
- Table utility commands | Delta Lakehttps://docs.delta.io/delta-utility/
- Best practices for performance efficiency | Databricks on AWShttps://docs.databricks.com/aws/en/lakehouse-architecture/performance-efficiency/best-practices
Be the first to comment
One email a morning. The day's playbooks for you.
Pick the categories you care about (or leave blank for everything). The digest is ranked by what you've actually been reading on this device, so it sharpens over time.