Integrating SQL in Spark 4.1 Declarative Pipelines: A Practical Guide
Explore how SQL integration in Spark 4.1 Declarative Pipelines simplifies data processing by focusing on transformations rather than execution mechanics. Learn about practical implementation, common pitfalls, and when this approach is most effective.
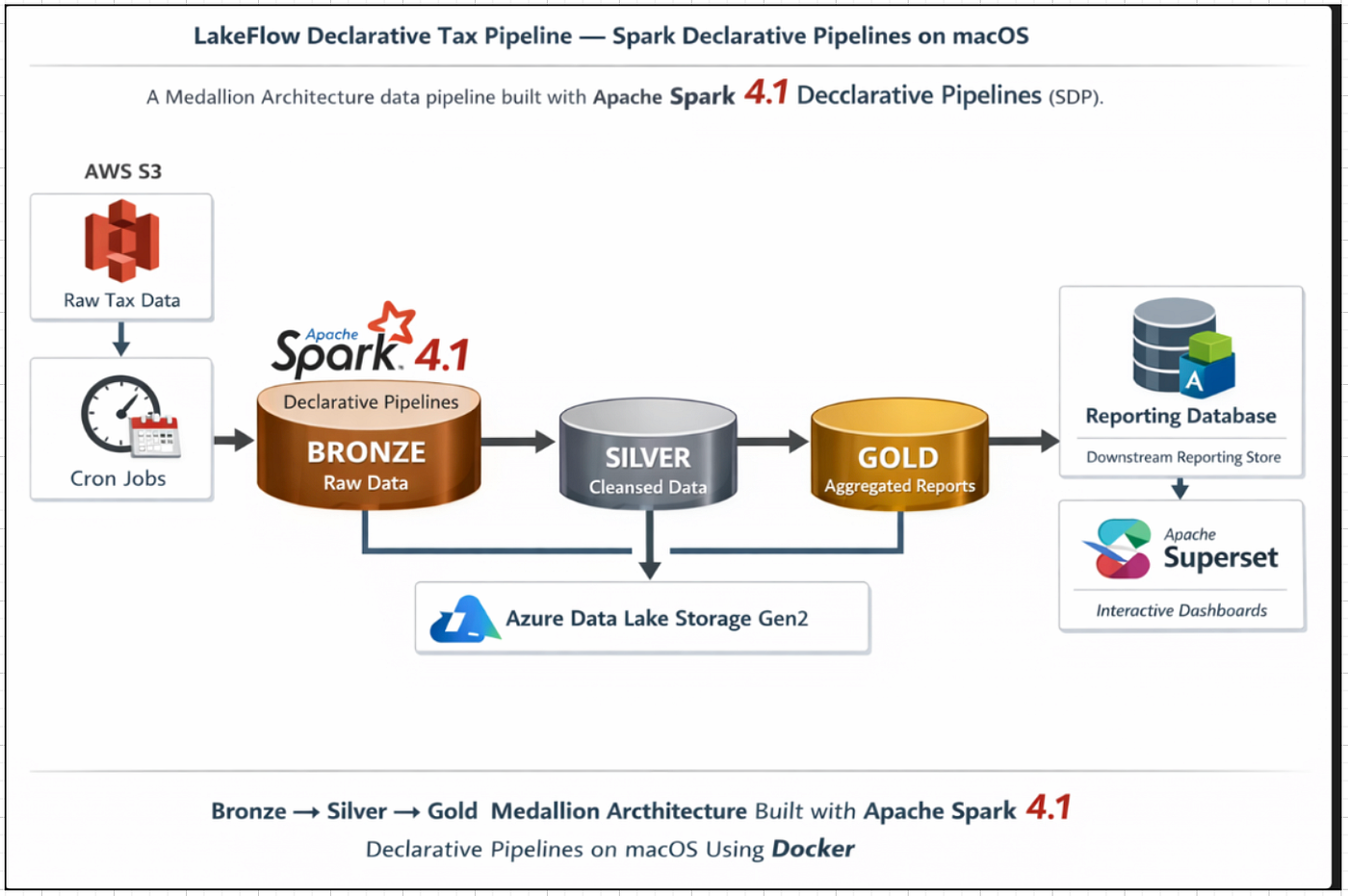
In the world of data engineering, managing complex ETL processes can be a daunting task, especially when dealing with both batch and streaming data. Apache Spark 4.1 introduces a new paradigm with Spark Declarative Pipelines (SDP), which allows engineers to define data transformations declaratively using SQL. This approach shifts the focus from managing execution details to specifying what the data should look like, thereby simplifying pipeline development and maintenance.
Why SQL Integration Matters
SQL's integration into Spark Declarative Pipelines is a significant advancement for data engineers. Traditionally, Spark jobs required explicit coding of each step, including data reading, transformation, and writing, along with managing execution sequences. With SDP, these tasks are abstracted away. Engineers can define desired outcomes using SQL, and Spark handles the orchestration, parallelism, and error management automatically. This not only reduces the complexity of the code but also enhances the reliability and testability of data pipelines[1][2].
Understanding the Declarative Approach
At its core, SDP allows you to define what your data should look like without worrying about how to achieve it. This is done through SQL statements that describe the state of tables and the transformations required. For example, you can create a streaming table with a simple SQL command:
CREATE STREAMING TABLE target_table AS SELECT * FROM STREAM source_table
This statement automatically sets up a flow that reads from source_table and writes to target_table, handling new data as it arrives[1]. The declarative nature of this setup means that Spark takes care of the execution order and parallel processing, which is particularly beneficial in complex pipelines with multiple dependencies.
Walking Through a SQL-Based Pipeline
Let's consider a practical example where we need to process order data from a Kafka topic, update a customer dimension table, and create a fact table of orders. Using SDP, you can define these transformations in SQL:
CREATE STREAMING TABLE raw_orders AS SELECT * FROM STREAM kafka_orders CREATE MATERIALIZED VIEW dim_customer AS SELECT DISTINCT customer_id, customer_name FROM raw_orders CREATE STREAMING TABLE fact_orders AS SELECT o.order_id, c.customer_name, o.amount FROM raw_orders o JOIN dim_customer c ON o.customer_id = c.customer_id
In this setup, SDP automatically manages the dependencies: raw_orders and dim_customer are updated in parallel, and fact_orders is updated once the upstream tables are ready[2]. This approach not only simplifies the pipeline definition but also optimizes execution by leveraging Spark's parallel processing capabilities.
Common Mistakes and How to Avoid Them
One common mistake when using SQL in SDP is underestimating the importance of defining clear dependencies and data flows. Without explicit dependencies, you might encounter unexpected execution orders or data inconsistencies. Another pitfall is not considering the performance implications of complex SQL queries, which can lead to inefficient execution plans and increased latency.
To avoid these issues, ensure that your SQL statements are optimized for performance and clearly define the relationships between datasets. Regularly monitor the execution plans and performance metrics to identify bottlenecks and optimize your queries accordingly[1][6].
When to Use SQL in Declarative Pipelines
SQL integration in Spark Declarative Pipelines is ideal for scenarios where you need to manage complex data transformations with minimal code. It is particularly effective in environments where data engineers are familiar with SQL and prefer a declarative approach to pipeline development. However, if your pipeline requires highly customized logic or intricate control over execution, a more traditional imperative approach might be necessary.
In conclusion, SQL integration in Spark 4.1 Declarative Pipelines offers a powerful tool for simplifying data processing tasks. By focusing on what the data should look like rather than how to process it, engineers can build more reliable and maintainable pipelines. As with any tool, understanding its strengths and limitations is key to leveraging its full potential in your data engineering projects.
- Spark Declarative Pipelines Programming Guide - Spark 4.1.1 Documentationhttps://spark.apache.org/docs/latest/declarative-pipelines-programming-guide.html
- Introducing Apache Spark® 4.1 | Databricks Bloghttps://www.databricks.com/blog/introducing-apache-sparkr-41
- ML Pipelines - Spark 4.1.1 Documentationhttps://spark.apache.org/docs/latest/ml-pipeline.html
- Spark Connect Overview - Spark 4.1.1 Documentationhttps://spark.apache.org/docs/latest/spark-connect-overview.html
- Quick Start - Spark 4.1.1 Documentationhttps://spark.apache.org/docs/latest/quick-start.html
- SQL Reference - Spark 4.1.1 Documentationhttps://spark.apache.org/docs/latest/sql-ref.html
- JDBC To Other Databases - Spark 4.1.1 Documentationhttps://spark.apache.org/docs/latest/sql-data-sources-jdbc.html
- How to get started with Spark Declarative Pipelines (SDP) | Databrickshttps://www.databricks.com/discover/how-to-get-started-with-spark-declarative-pipelines
Be the first to comment
One email a morning. The day's playbooks for you.
Pick the categories you care about (or leave blank for everything). The digest is ranked by what you've actually been reading on this device, so it sharpens over time.