Transforming Data Engineering with Spark Declarative Pipelines
Spark Declarative Pipelines offer a streamlined approach to building data workflows, focusing on business logic while automating execution. This article explores how to leverage this framework to simplify ETL processes and improve pipeline reliability.
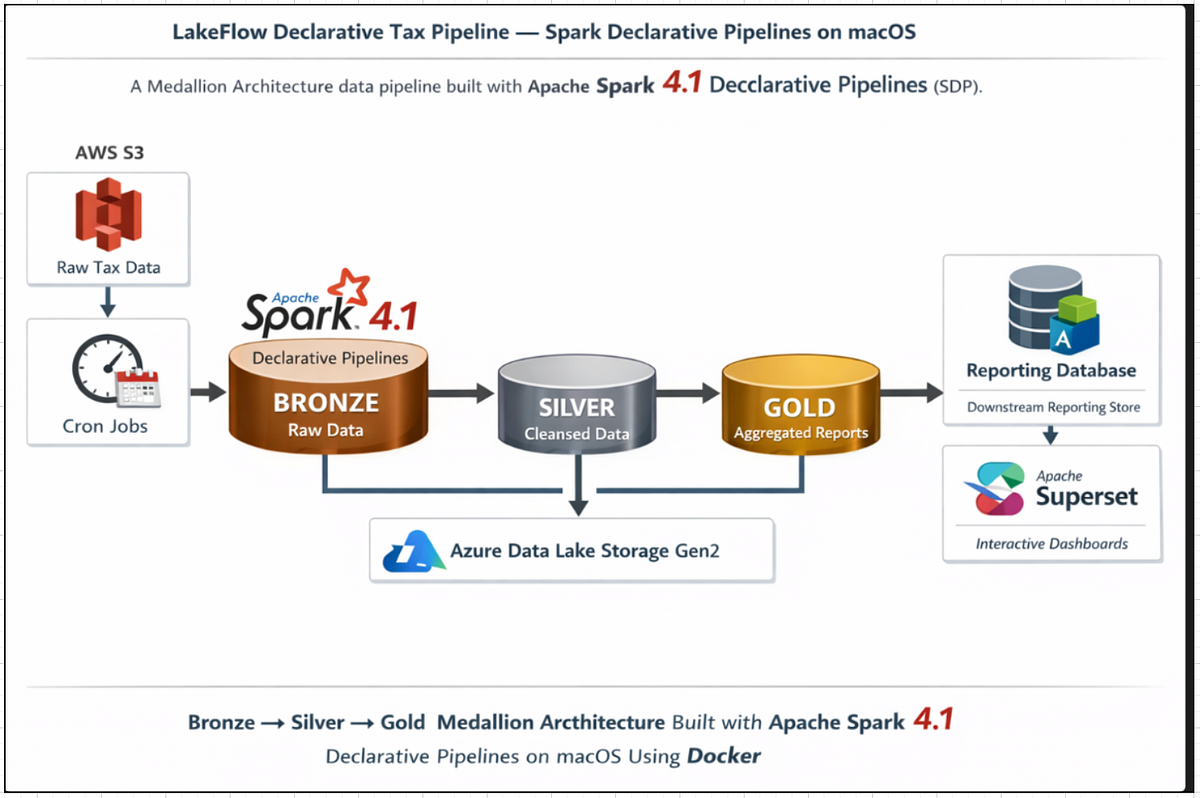
Introduction to Spark Declarative Pipelines
In the realm of data engineering, the complexity of managing Extract, Transform, Load (ETL) processes often becomes a bottleneck. Traditional imperative approaches require meticulous orchestration of each step, demanding significant effort in coding and maintenance. Enter Spark Declarative Pipelines (SDP), a framework designed to alleviate these burdens by shifting the focus from 'how' to 'what' you want to achieve with your data[1].
SDP is particularly beneficial for both batch and streaming data processing. It automates the orchestration, compute management, and error handling, allowing you to concentrate on defining the desired state of your data rather than the intricate details of execution[1]. This declarative approach is not only more intuitive but also enhances the reliability and maintainability of data pipelines.
Understanding the Core Concepts
At the heart of SDP are several key concepts: flows, datasets, and pipelines. A flow is the fundamental unit of data processing, capable of handling both streaming and batch semantics. It reads data from a source, applies user-defined transformations, and writes the results to a target dataset[1].
Datasets in SDP can be categorized into streaming tables, materialized views, and temporary views. Streaming tables are ideal for real-time data ingestion and processing, while materialized views are suited for complex analytical queries with precomputed results. Temporary views, on the other hand, are used for intermediate transformations without persisting data to storage[4].
A pipeline is a collection of flows and datasets, representing the entire data processing workflow. Pipelines are defined using a mix of Python and SQL, and they are managed through a YAML-formatted pipeline specification file[1].
Walking Through a Declarative Pipeline
Let's delve into how you can construct a simple ETL pipeline using SDP. Imagine you need to ingest data from a cloud storage system, apply transformations, and store the results in a data lake.
First, you define your pipeline in a YAML file, specifying the libraries and storage locations:
libraries: - path/to/your/python/files storage: /path/to/checkpoints
Next, in your Python code, you define a function to represent a table using the @dp.table decorator. This function returns a DataFrame that represents the transformed data:
@dp.table def dim_customer(): df = spark.read.format("csv").option("header", "true").load("/path/to/source/data") transformed_df = df.select("customer_id", "name", "email") return transformed_df
In this snippet, the dim_customer function reads data from a CSV file, selects relevant columns, and returns a DataFrame. The @dp.table decorator indicates that this function should result in a physical table in your data lake[2].
Once the pipeline is defined, SDP takes care of the execution order, parallelization, and error handling. You simply focus on defining the desired transformations and let the framework handle the rest.
Common Mistakes and How to Avoid Them
Transitioning to a declarative paradigm can be challenging, especially if you're accustomed to imperative programming. One common mistake is trying to micromanage the execution process, such as manually handling data writes. In SDP, you don't explicitly call a write operation; instead, you define the table as the result of a function or SQL query[2].
Another pitfall is misunderstanding the types of datasets. Choosing the wrong dataset type can lead to inefficient processing. For instance, using a materialized view for a high-frequency streaming workload can incur unnecessary compute costs. It's crucial to select the appropriate dataset type based on your specific use case[4].
When to Use Spark Declarative Pipelines
SDP is an excellent choice for scenarios where you need to streamline ETL processes, especially when dealing with complex transformations and real-time data ingestion. Its ability to automate orchestration and error handling makes it ideal for large-scale data engineering tasks[7].
However, if your workflow requires fine-grained control over execution or involves highly customized processing logic, you might find the declarative approach limiting. In such cases, a hybrid approach that combines declarative and imperative paradigms might be more suitable.
In conclusion, Spark Declarative Pipelines offer a powerful framework for simplifying data engineering workflows. By focusing on the 'what' rather than the 'how', you can build more reliable, maintainable, and scalable data pipelines, freeing up time to focus on deriving insights from your data[1][3][7].
- Spark Declarative Pipelines Programming Guide - Spark 4.1.1 Documentationhttps://spark.apache.org/docs/latest/declarative-pipelines-programming-guide.html
- Spark Declarative Pipelines “How-To” Series. Part ... - Databricks Community - 149180https://community.databricks.com/t5/technical-blog/spark-declarative-pipelines-how-to-series-part-1-how-to-save/ba-p/149180
- Getting the Most Out of Spark Declarative Pipelines: Deep Dive on What’s New and Best Practices | Databrickshttps://www.databricks.com/dataaisummit/session/getting-most-out-spark-declarative-pipelines-deep-dive-whats-new-and
- Best practices for Lakeflow Spark Declarative Pipelines | Databricks on AWShttps://docs.databricks.com/aws/en/ldp/best-practices
- Tutorial: Build an ETL pipeline with Lakeflow Spark Declarative Pipelines | Databricks on AWShttps://docs.databricks.com/aws/en/getting-started/data-pipeline-get-started
- Spark Declarative Pipelines use in All-purpose com... - Databricks Community - 144076https://community.databricks.com/t5/data-engineering/spark-declarative-pipelines-use-in-all-purpose-compute/td-p/144076
- Lakeflow Spark Declarative Pipelines concepts | Databricks on AWShttps://docs.databricks.com/aws/en/ldp/concepts
- What’s New in Data Engineering and Streaming - January 2024 | Databricks Bloghttps://www.databricks.com/blog/whats-new-data-engineering-and-streaming-january-2024
Be the first to comment
One email a morning. The day's playbooks for you.
Pick the categories you care about (or leave blank for everything). The digest is ranked by what you've actually been reading on this device, so it sharpens over time.